A markup syntax for lawyers
This is a continuation of my previous blog on a contract editor for lawyers.
This blog proposes a custom markup syntax tailored to drafting contracts.
I have a working draft of the markup syntax on my Github. Feedback is welcomed.
Preliminary research
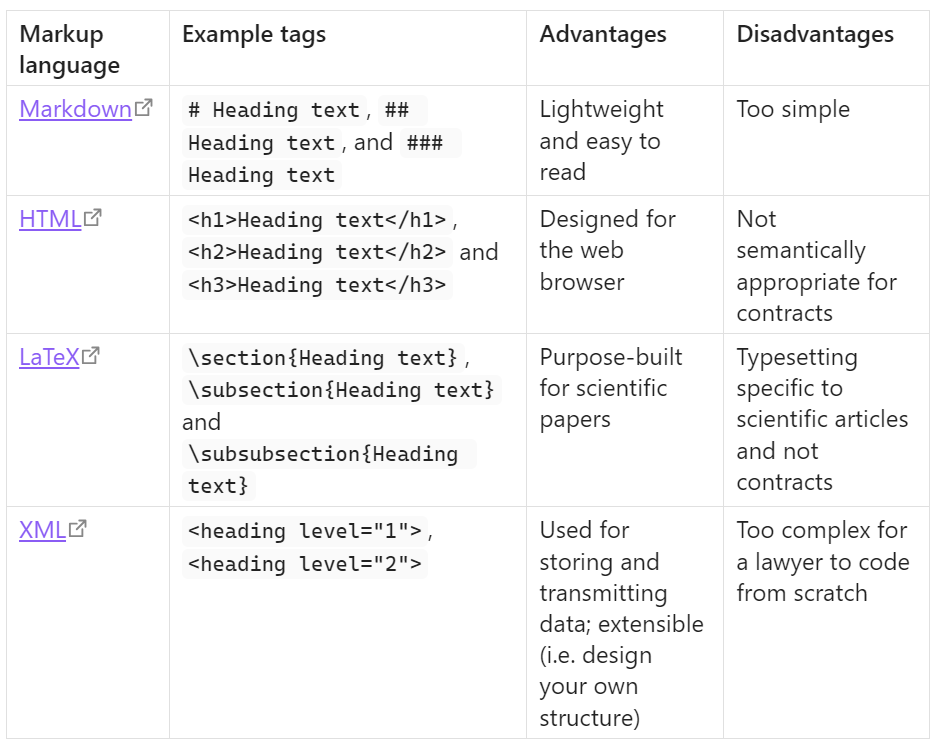
Overview of different markup languages
Each markup language uses their own 'tags' to control the structure, presentation or description of data (which in most cases, would be text).
This video discusses the history of markup languages from the perspective of writing documentation, providing examples of tags they've used and their use cases.
Scribe is also another markup language which heavily influenced those languages above. I take lots of inspiration from it too.
Types of markup
There are three main general categories of electronic markup, articulated in Coombs, Renear, and DeRose (1987), (https://en.wikipedia.org/wiki/Markup_language#cite_note-6) and Bray (2003) (https://en.wikipedia.org/wiki/Markup_language#cite_note-7).
Presentational markup
The kind of markup used by traditional word-processing systems: binary codes embedded within document text that produce the WYSIWYG ("what you see is what you get") effect. Such markup is usually hidden from human users, even authors and editors. Properly speaking, such systems use procedural and/or descriptive markup underneath but convert it to "present" to the user as geometric arrangements of type.
This is what Microsoft Word is.
Procedural markup
Markup is embedded in text which provides instructions for programs to process the text. Well-known examples include troff, TeX, and Markdown. It is assumed that software processes the text sequentially from beginning to end, following the instructions as encountered. Such text is often edited with the markup visible and directly manipulated by the author. Popular procedural markup systems usually include programming constructs, especially macros, allowing complex sets of instructions to be invoked by a simple name (and perhaps a few parameters). This is much faster, less error-prone, and more maintenance-friendly than re-stating the same or similar instructions in many places.
Descriptive markup
Markup is specifically used to label parts of the document for what they are, rather than how they should be processed. Well-known systems that provide many such labels include LaTeX, HTML, and XML. The objective is to decouple the structure of the document from any particular treatment or rendition of it. Such markup is often described as "semantic". An example of a descriptive markup would be HTML's <cite> tag, which is used to label a citation. Descriptive markup — sometimes called logical markup or conceptual markup — encourages authors to write in a way that describes the material conceptually, rather than visually.[8]
I propose to use a combination of procedural (taking inspiration from Markdown) and descriptive markup (taking inspiration from LaTeX).
How is a language interpreted?
Why I can't just use regex
The most obvious is the lack of recursion: you cannot find a (regular) expression inside another one, unless you code it by hand for each level.
Regular expressions have no memory in the sense that they can’t remember what they matched earlier in the input. Because of that, they don’t know how to match up left and right curlies.
Also, its not scalable.
Formal grammar
First, a formal grammar must be defined. A formal grammar is a list of rules that define how each construct can be composed. For example, a rule for an if statement could specify that it must starts with the “if” keyword, followed by a left parenthesis, an expression, a right parenthesis and a statement. This article describes elements of a formal grammar.
The most used format to describe grammars is the Backus-Naur Form (BNF), which also has many variants, including the Extended Backus-Naur Form.
Lexer and parser
See https://tomassetti.me/parsing-in-javascript/
See also https://tomassetti.me/antlr-mega-tutorial/
A parser is usually composed of two parts: a lexer, also known as scanner or tokenizer, and the proper parser. A lexer and a parser work in sequence: the lexer scans the input and produces the matching tokens, the parser scans the tokens and produces the parsing result.
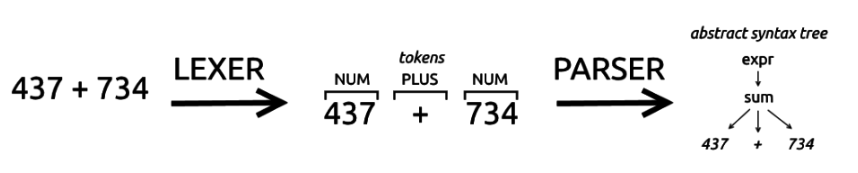
Parser generators
Why to use a parser generator like ANTLR instead of building your own? Productivity - it is difficult to update your parser every time the formal grammar changes.
From a formal grammar, there are tools to auto-generate code for a parser (e.g. using ANTLR). The basic workflow of a parser generator tool is quite simple: you write a grammar that defines the language, or document, and you run the tool to generate a parser usable from your JavaScript code.
ANTLR provides two ways to walk the AST, instead of embedding actions in the grammar: visitors and listeners. The first one is suited when you have to manipulate or interact with the elements of the tree, while the second is useful when you just have to do something when a rule is matched.
Custom XML based markup language
In trying to find resources on how to create markup languages, I came across this publication explaining how XML is used in practice:
Before you get too far into this tutorial, I have to make a little confession. When you create an XML document, you aren't really using XML to code the document. Instead, you are using a markup language that was created in XML. In other words, XML is used to create markup languages that are then used to create XML documents. The term "XML document" is even a little misleading because the type of the document is really determined by the specific markup language used. So, as an example, if I were to create my very own markup language called MML (Michael's Markup Language), then the documents I create would be considered MML documents, and I would use MML to code those documents. Generally speaking, the documents are still XML documents because MML is an XML-based markup language, but you would refer to the documents as MML documents. The point of this discussion is not to split hairs regarding the terminology used to describe XML documents. It is intended to help clarify the point that XML is a technology that enables the creation of custom markup languages. If you're coming from the world of HTML, you probably think in terms of there being only one markup languageHTML. In the XML world, there are thousands of different markup languages, with each of them applicable to a different type of data. As an XML developer, you have the option of using an existing markup language that someone else created using XML, or you can create your own. An XML-based markup language can be as formal as XHTML, the version of HTML that adheres to the rules of XML, or as informal as my simple Tall Tales trivia language. When you create your own markup language, you are basically establishing which elements (tags) and attributes are used to create documents in that language. Not only is it important to fully describe the different elements and attributes, but you must also describe how they relate to one another. For example, if you are creating a markup language to keep track of sports information so that you can chart your local softball league, you might use tags such as
<schedule>, <game>, <team>, <player>, and so on. Examples of attributes for the player element might includename, hits, rbis, and so on.
Closest contract-specific markup language I could find
Most markup languages for contractual drafting focus on creating Smart Legal Contracts (i.e. self-executing contracts). For a lawyer, this is unnecessary 99.99% of the time and adds unnecessary complexity to programmatic contractual drafting.
The closest markup syntax I have found to what I want to do is within the Accord project, named CiceroMark and TemplateMark.
CiceroMark allows for the parsing of clauses, such as the below:

TemplateMark allows for defining variables, such as defined terms:
Upon the signing of this Agreement, {{buyer}} shall pay {{amount}} to {{seller}}.
However, that is the extent of what you can do with that markup (other functionality is not necessarily useful for a non-smart contract).
Goals
To develop a markup syntax, I need to follow these steps:
- Design the syntax
- Define a grammar
- Develop a parser
- Lexer: break input into tokens
- Parse tree: tree-like structure that represents nested elements and relationships
- Develop a renderer
Note: I do not want to create a Domain Specific Language (DSL). A DSL is an expressive, compact way to describe operations, configurations, or behaviors in that domain (for example, SQL for databases, Regular Expressions for pattern matching, or Terraform for infrastructure as code). A markup syntax, rather, is used to describe or annotate the structure and presentation of content. It focuses on organising and representing data or documents. Developing a DSL to simply draft contracts would be overkill as logic, conditionals, loops and expressions are not necessary when drafting contracts.
Formal Grammar
Setting up ANTLR4 was a hassle, but with thanks to resources like this video and this VSCode extension, I was able to set it up for parser generation and debugging.
Some resources for ANTLR4:
- The ANTLR Mega Tutorial;
- example grammars from popular languages;
- ANTLR Lab for easy testing; and
- The Definitive ANTLR4 Reference, 2nd Edition.
The parser and lexer rules I've defined can be found in /contract-editor/app/formal-grammar.
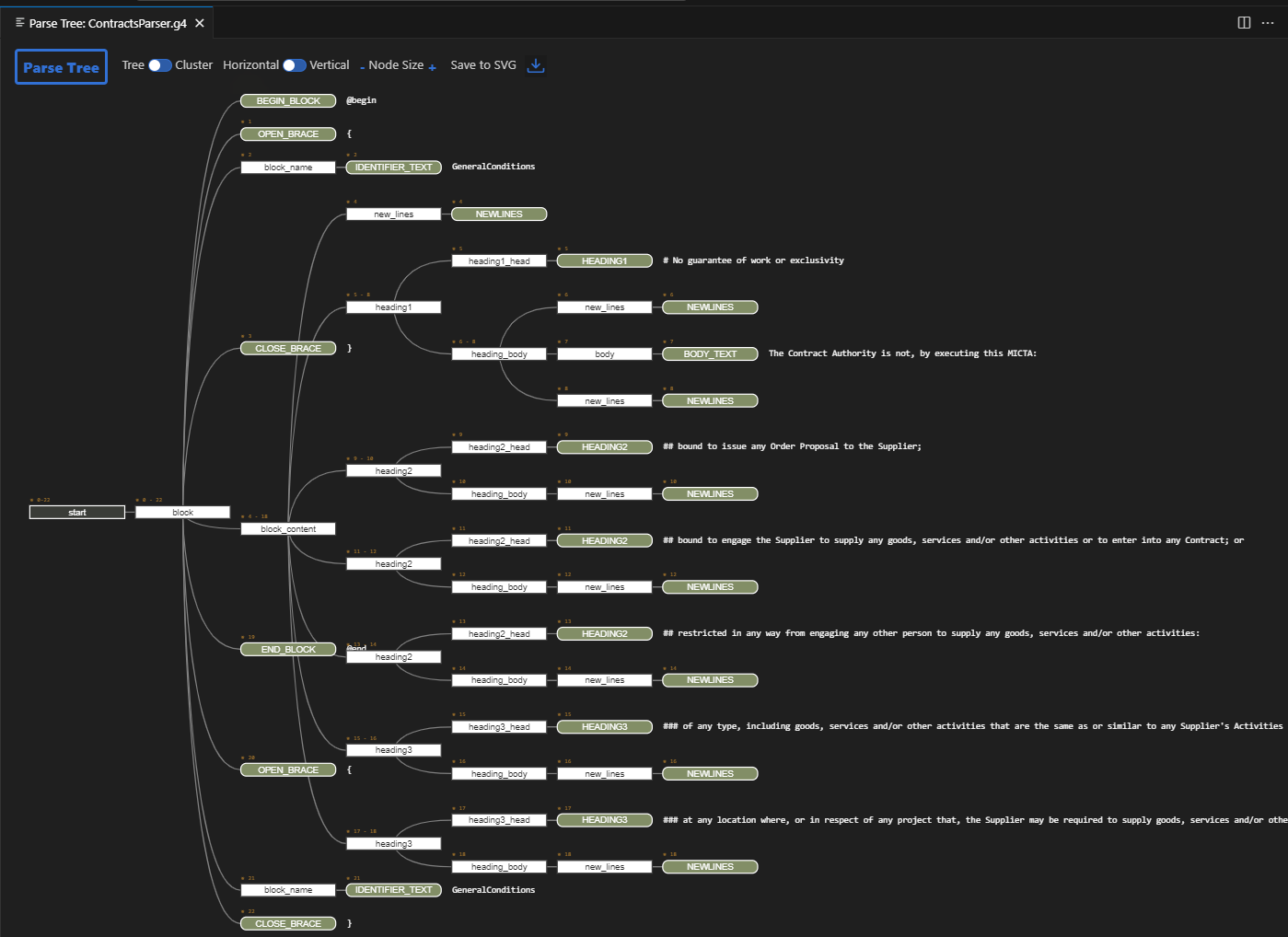
The purpose of the formal grammar is to generate a parse tree. It is a heirarchical representation of the text data as defined by the grammar. For example, the following text produces the parse tree below:

Transforming XML
Once my formal grammar is set up and I can parse text into my own custom XML format, I will need to transform this XML into HTML and other formats.
For this, we use XSL (eXtensible Stylesheet Language) (a styling language for XML). XSLT stands for XSL Transformations.
XSLT is a language for transforming XML documents. XPath is a language for navigating in XML documents. XQuery is a language for querying XML documents.
CSS is style sheets for HTML (which ofc has pre-defined tags), whereas XSL are stylesheets for XML (which does not have any pre-defined tags).